Revolucionando la Computación Cuántica: Control Cuántico Mejorado a través del Aprendizaje Profundo
Computación cuántica avanza con control de qubits mediante Aprendizaje por Refuerzo Profundo, reduciendo errores. Publicado en Nature Partner Journal Información Cuántica. Mejora abre posibilidades en simulación cuántica, química cuántica y busca de supremacía cuántica.
CIENTÍFICOS/PERIODISTICOS
Franco Mansilla
11/21/2023
En un avance significativo para superar los desafíos en la construcción de computadoras cuánticas, un equipo de investigadores ha presentado un innovador marco de control cuántico utilizando técnicas de aprendizaje profundo. Este enfoque promete reducir errores y tiempos de puerta, allanando el camino para aplicaciones más amplias en simulación cuántica y química cuántica.
Abordando Desafíos en la Construcción de Computadoras Cuánticas
Uno de los principales obstáculos en la realización de computadoras cuánticas radica en los qubits, las unidades fundamentales de la computación cuántica. Estos pueden ser afectados por diversos factores, desde fotones extraviados hasta interferencias en los controles clásicos. Para mejorar la capacidad computacional, es esencial abordar los problemas prácticos que limitan las aplicaciones de los dispositivos cuánticos a corto plazo.
Nuevo Paradigma: Control Cuántico Universal a través del Aprendizaje Profundo
En el estudio titulado "Control Cuántico Universal a través del Aprendizaje por Refuerzo Profundo", los investigadores presentan un marco de control cuántico generado mediante el aprendizaje por refuerzo profundo. Este enfoque encapsula varias preocupaciones prácticas en la optimización del control cuántico, logrando reducciones significativas en el error de la puerta lógica cuántica y en el tiempo de puerta.


Superando Errores Críticos en la Computación Cuántica
Uno de los errores más perjudiciales en la computación cuántica es la fuga de información, donde la información cuántica se pierde durante el cálculo. El nuevo paradigma de control cuántico aborda este problema al desarrollar una función de coste integral que permite una optimización conjunta sobre los errores de fuga, violaciones de las condiciones de contorno y la fidelidad de la puerta.


Aprendizaje por Refuerzo Profundo: Herramienta Clave para la Optimización
La clave para este avance radica en la aplicación de la política de aprendizaje por refuerzo profundo (RL). A diferencia de los métodos existentes, esta política se representa independientemente del costo de control, lo que resulta en soluciones más robustas y eficientes para controlar las fluctuaciones en sistemas cuánticos de alta dimensión.
Resultados Impresionantes: Reducción de Errores y Tiempos de Puerta
Las simulaciones numéricas muestran resultados impactantes. Bajo este nuevo marco, se logra una reducción de 100 veces en los errores de puertas cuánticas, junto con tiempos de puerta significativamente reducidos. Esto representa un avance crucial en comparación con enfoques tradicionales, allanando el camino para el desarrollo de computadoras cuánticas más eficientes.


Diagrama de Red Neuronal para Aprendizaje por Refuerzo
Este diagrama ofrece una visión más clara y concisa del modelo utilizado, proporcionando a los lectores una representación visual de los conceptos discutidos en este emocionante avance en la computación cuántica.
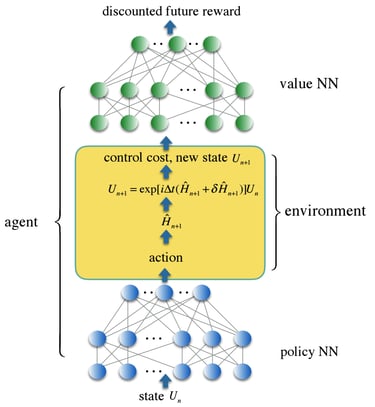
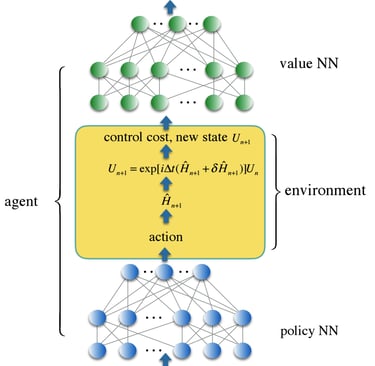
Diagrama de flujo de un modelo de red neuronal para el aprendizaje por refuerzo. Los círculos azules y verdes representan nodos y las líneas negras representan bordes. Los nodos están dispuestos en tres capas, con las capas superior e inferior representando la red neuronal y la capa intermedia representando la interacción agente-entorno. La capa superior está etiquetada como “futuro descontado” y la capa inferior está etiquetada como “estado U_t”. La capa intermedia está etiquetada como “costo de control, nuevo estado U_t+1” y “acción H_t”. El diagrama también incluye un cuadro amarillo etiquetado como “policy NN” y un cuadro verde etiquetado como “value NN”.
Este tipo de modelo se utiliza en el aprendizaje por refuerzo, que es una técnica de aprendizaje automático que se utiliza para entrenar a un agente a tomar decisiones en un entorno determinado.
Este emocionante trabajo resalta la importancia de fusionar técnicas de aprendizaje automático y algoritmos cuánticos para mejorar la capacidad computacional de las computadoras cuánticas. Aunque se necesitan más experimentos, este nuevo enfoque ofrece un paso crucial hacia la construcción de dispositivos cuánticos más potentes y versátiles, impulsando el futuro de la computación cuántica.
¡No te pierdas las novedades!
INNOVADUCATE S. A. S.
CUIT: 30-71863797-6
Domicilio: Juan Días Solís 959